中二病をこじらせたおじさんが今一番口にしたい言葉(当ブログ調べ)「Stable Diffusion」の新しいバージョンStable Diffusion 3.5(以下SD 3.5)が2024年10月に発表されました。ローカル環境構築も変わってたので、新しく画像生成AIを始める人の参考になれば幸いです。

画像生成AIとは
簡単に言うとコンピューターが勝手に画像を書いてくれる。AI(人口知能)です。海辺の風景書いてくださいとか、女の子書いてとか指示与えると画像を生成してくれます。
有名なサービスといえば、本記事でも触れる「Stable Diffusion」以外にも「Midjourney」やChatGPTから派生した「Visual ChatGPT」などもあるようです。以前にも画像生成AIについての記事を書いていたりしますので、そちらも併せて読んでいただければ幸いです。
ハードウェア環境とComfyUI
ハードウェア環境は前回の「画像生成AIを試すおじさん」とそんなに環境は変わっておりません。
・CPU: AMD Ryzen3 5700X
・メモリ: DDR4 48GB
・Graphics: nVIDIA GeForce RTX 2070、 GDDR: 8GB
・OS: Microsoft Windows 10
また、画像生成AI分野ではGraphicsの性能(特に nVIDIA製のやつが最適化されてるっぽい)がものを言います。昨今の半導体不足等でグラフカードが高騰しており、そちらの方に資金をかけてられません。
最近ローカル環境ではComfyUIというユーザーインターフェースを使って生成するのが主流っぽいです。これを使うことの利点としては、インプット、アウトプットに関連するソフトウェアをモジュール化(ノード化)して組み合わせに自由度を持たせることをやっているみたいです。
SD 3.5も「最新のComfyUIで行うこと~」みたいな情報がのっていましたので、それに準じて環境を構築していこうと思います。
Comfy UIの設定
- Comfy UIのGitHubページに行ってページの真ん中ぐらいにある「Direct link to download」をクリックして、必要なファイルをダウンロードしてきます。
2. ダウンロードしたファイルを適当なフォルダを作成し、解凍します。
3. モデルをダウンロードしてきて、「解凍フォルダ」→「ComfyUI_windows_portable」→「ComfyUI」→「models」→「checkpoints」フォルダ内に好みのモデルデータを配置します。
モデルって何?という話ですが、生成AIに絵を描かせる際にベースになるデータと考えてくれればよいです。2D、3Dk、人物、風景など得意不得意があり自分の好みに合わせて採用してください。civitaiにはたくさんのモデルがあります。選びきれないという人がいたら、googleで「stable diffusion モデル おすすめ」などで検索してから調べるのがよいと思います。
*「解凍フォルダ」→「ComfyUI_windows_portable」フォルダ内に「run_nvidia_gpu.bat」があるので、ダブルクリックして実行するとcomfy UIがwebのUIとして立ち上がってきます。
Stable Diffusion 3.5を設定する
メモリを32GB以上搭載しているのであれば、largeモデルがおすすめということで、largeモデルでの構築を進める。SD 3.5にはmidium(軽量)モデル、large(通常)モデル、large-turbo(上流)モデルの3つが提供されています。
モデルに関しては、10GB前後のファイルを複数導入することになるのでローカル環境にはそれなりの空き容量(50GB~100GBぐらい)が必要になること、ダウンロード通信量も多くなるのであらかじめ注意したほうがよいです。
SD 3.5を始めるにあたり、ファイルが配布されているサイトHagging Faceのアカウントを登録をする必要があるので、あらかじめ用意しておく。追加で名前の入力をしないとファイルのダウンロードをさせてもらえない場合もあるので、注意が必要です。
- チェックポイントモデルの導入
以下のファイルをダウンロード
stable-diffusion-3.5-large (sd3.5_large.safetensorsを保存する)
その後「解凍フォルダ」→「ComfyUI_windows_portable」→「ComfyUI」→「models」→「checkpoints」にダウンロードしたファイルを格納する。

2. テキストエンコーダーの導入
以下3つのファイルをダウンロード
clip_g.safetensor
clip_l.safetensors
t5xxl_fp16.safetensors
その後「解凍フォルダ」→「ComfyUI_windows_portable」→「ComfyUI」→「models」→ 「clip」にダウンロードしたファイルを格納する。
3. ワークフローファイルの導入と設定
Hagging Faceからファイル「sd3.5-t2i-fp16-workflow.json」をダウンロードして適当なフォルダに格納する(後でcomfyUIから読み込むことになるので、どこでもよいが、便宜上「解凍フォルダ」→「ComfyUI_windows_portable」→「ComfyUI」に配置)する。
ComfyUIを起動(run_nvidia_gpu.batを)実行します。webにUIが表示されたら、メニュー内の「Workflow」からOpenをクリックして先ほど配置した~.jsonファイルを選びます。
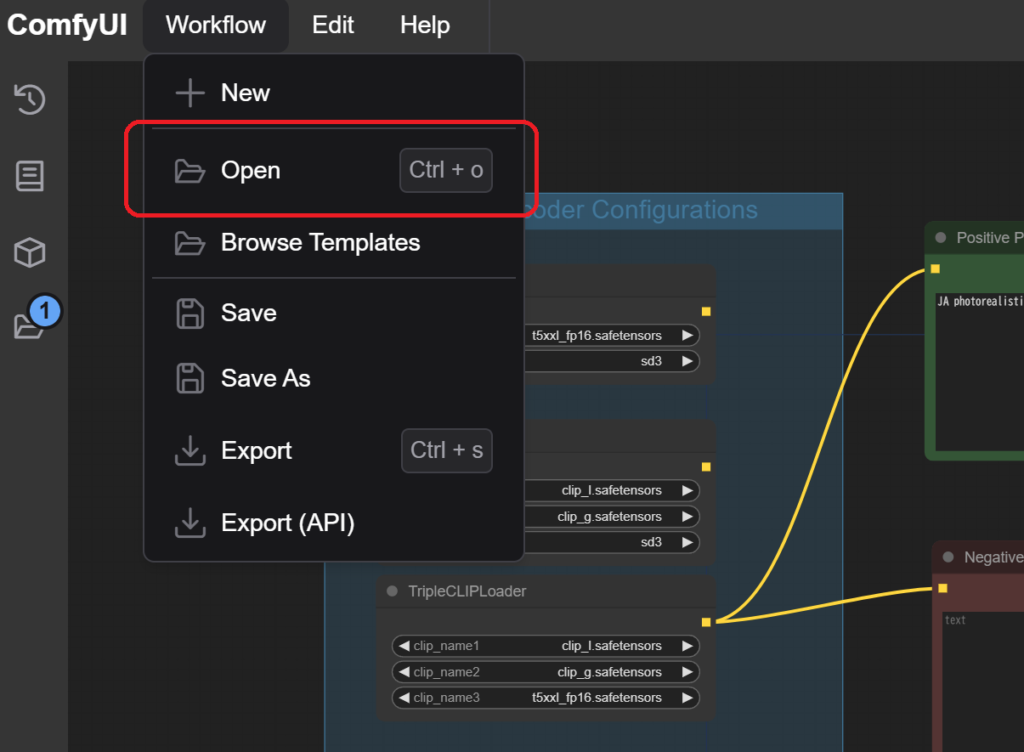
これにて、ひとまずのSD 3.5 環境は構築されます。
SD 3.5(comfyUI)の使い方
環境が整いましたら、実際に画像を生成してみましょう。
画像を生成するためのプロンプト(指示を与えると部分)は、画面中央部にあります”Positive Prompt”に書き込みます。反対に生成してほしくない要素は”Negative Prompt”に書き込みます。プロンプトは日本語には対応していないので英語で与えます。
プロンプトの入力を終えたら、”Queue”ボタンをクリックすると画像生成が始まります。
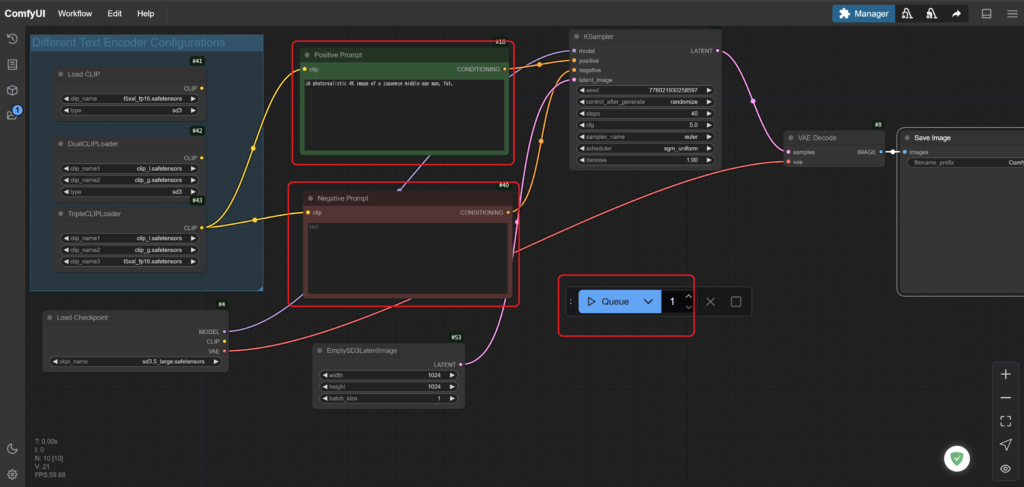
生成された画像は、「解凍フォルダ」→「ComfyUI_windows_portable」→「ComfyUI」→ 「Output」に保存されていきます。
適当に作ってみた画像がいかになります。



まとめ
SD 3.5の環境を構築してみましたが、以前 SD 3.0 Forge環境を構築したのと比べると全然生成スピードが遅いです。
Comfy UIが2分30秒程度に対し、Forgeの環境は30秒程度、画像のサイズに違いがある成果もしれませんが、ちょっとイライラしますね。あとは画像AIの宿命なのか、指とか腕の表現がたまに気持ち悪いものが出てきます。もうちょっといろいろなことことを勉強して、画像生成のスピードが速くなれば面白いおもちゃになると思いました。

最後までお読みいただきありがとうございました。